23 kwietnia 2026 roku OpenAI wypuściło swój najnowszy model sztucznej inteligencji, GPT 5.5. Premiera nastąpiła zaledwie siedem tygodni po debiucie GPT 5.4, co mówi wiele o tempie, w jakim branża AI toczy swój wyścig. Open AI kontynuuje tryb cichych premier, i publikuje najnowszy model z zaskoczenia, licząc na efekt „wow”, bez ryzyka zawiedzenia oczekiwań.
Czy w tym wypadku udało się osiągnąć planowany efekt? Jak najbardziej. Model radzi sobie lepiej z kodowaniem, oraz rozumowaniem, zwłaszcza przy dłuższych tekstach i większych zadaniach. Lepiej też „domyśla się” tego czego chce użytkownik (jest to duży skok w porównaniu do poprzednich wersji). Ulepszona została też integracja z innymi narzędziami, model radzi sobie dużo lepiej z generowaniem tabel i dokumentów, pod tym względem zaczął dorównywać Claude.
Przy czym skok w jakości programowania widać dopiero jeśli Chat GPT 5.5. pracuje w codexie, czy innym programie do pisania programów. Kod pisany bezpośrednio w aplikacji ma sporo problemów.
Na uwagę zasługuje również lepsze generowanie grafik, moduł graficzny w końcu został zintegrowany z modele rozumującym (podobnie jak to jest w przypadku nano banana pro), tak więc w Chat GPT można teraz generować infografiki, i działa to lepiej niż w Gemini. Pisanie tekstów to najsłabsza strona nowego modelu. Choć model oczywiście radzi sobie z tym dość dobrze, to nie widać tu takiego skoku jakości jak w innych dziedzinach, gdzie GPT 5.5. jest liderem, lub jest na drugim miejscu, tuż za innym najlepszym modelem.
Spis treści
Open AI wraca na pozycje lidera.
Od premiery Chat GPT 5, (sierpień 2025) Open AI nie miało dobrej passy. Słynna piątka była zapowiadana właściwie od premiery GPT 3.5 (czyli pierwszego publicznie dostępnego modelu LLM, od którego zaczęła się obecna rewolucja AI. GPT 5 był zapowiadany jako gigantyczna rewolucja która miała zmienić świat, a okazała się jedynie nieco lepszym modelem niż poprzednie modele od Open AI.
W między czasie, Gemini oraz Claude zdążyło wyprzedzić GPT w wielu dziedzinach. Nowe premiery z serii GPT.5 nie ratowały sytuacji. Model radził sobie dobrze przy kodowaniu, i dobrze sobie radził mając precyzyjne instrukcje, tak więc był ceniony przez programistów i specjalistów, ale zwykli użytkownicy powoli przechodzili na inne modele. Choć oczywiście Chat GPT nadal był popularnym modelem, ale powoli tracił on pozycje czempiona, którą miał od samego początku obecnego boomu na AI.
GPT 5.5. odwraca tę sytuacje.

Główne zalety nowego modelu
Największy wzrost jakości widać przy generowaniu grafik (choć za to odpowiada nowy model GPT image 2.0, a nie bezpośrednio GPT.5.5. Ogromny skok w jakości widać przy kodowaniu, rozumowaniu, oraz przy tworzeniu dokumentów.
Chat GPT Claude, Gemini, Grok – co wybrać, i jak premiera Chat gpt 5.5. wpływa na wybór?
Premiera nowszej wersji sprawia że Chat GPT dogonił Claude w kwestii kodowania, rozumowania, pisania i researchu. Szczególnie istotna jest zdolność operowania na tabelach i dokumentach (funkcję te Claude ma juz od dawna).
Osobiście uważam że Claude nadal jest w tych rzeczach lepszy. W Claude mamy od razu podgląd takich dokumentów, w Chat GPT podgląd jest dostępny jedynie dla tabel, efekt generowania dokumentu można poznać dopiero po pobraniu pliku. Natomiast Chat GPT posiada przewagę w postaci generowania grafik (i infografik). Claude takiej funkcji w ogóle nie posiada (tzn. pozwala generować grafiki za pomocą kodu w SVG, ale ma to swoje ograniczenia).
Claude nie potrafi w takich grafikach umieszczać obrazków (np. logotypów modeli, chyba że poświęcimy dodatkowy czas na generowanie logotypów w SVG)

Infografiki pełnią nie tylko funkcję estetyczną, są one też dobrym sposobem do robienia podsumowania tekstu, ułatwiają one zrozumienie zagadnienia. Tak więc warto z nich korzystać, nawet jeśli ostatecznie nie użyjesz takich infografik publicznie.
Chat GPT 5.5. a Gemini
Chat GPT przegonił Gemini w kwestii generowania infografik. Przez długi czas była to główna przewaga modelu Nanobana pro dostępnego w Gemini. W przypadku generowania tekstu, różnice były minimalne, i nawet jeśli dany model był lepszy, to za pomocą odpowiednich promptów dało się osiągnąc podobny efekt w innym. Jeśli jednak potrzebowałeś, infografik, to Gemini było jedyną opcją. W przypadku generowania infografik, chat GPT 5.5. znacząco przegonił aplikacje od Google.
Generowanie filmów, tu Gemini i Grok wygrywają z Chat GPT
Płatna wersja Gemini daje możliwość generowania 3 filmów dziennie, płatny Grok pozwala na generowanie większej ilości filmów. Nadal jest to bardziej zabawka niż porządne narzędzie, ale da się już w tym robić użyteczne filmy. A biorąc pod uwagę rozwój technologii, dobrze jest znać podstawy generowania filmów.
Open Ai długo udostępniało w płatnym planie apkę do generowania filmów Sora, ale niedawno z tego zrezygnowali, żeby skupić się na głównym modelu.
Przy czym zarówno Grok, jak i Gemini nie pokrywają całego tematu tworzenia filmów w AI, jeśli więc poza bawieniem się, chcesz stworzyć parominutowy film, to konieczne jest skorzystanie z innych narzędzi.
Ogólna przewaga Chata GPT nad resztą, (najbardziej złożona aplikacja)
Chat GPT ma po prostu najwięcej funkcji. Jeśli więc nie widzisz różnicy w jakości samego modelu językowego, dodatkowe funkcje GPT (takie jak złożona personalizacja, tryb agentowy, itd.) mogą być dla Ciebie dodatkową przewagą. Nie są to kluczowe funkcje, w wielu przypadkach są to po prostu drobne udogodnienia.

Generowanie grafik, i infografik. GPT prześcignął Gemini.
Przez długi czas NanoBanana Pro było niekwestionowanym liderem w generowaniu prostych infografik. Nano Banana 2 to pierwszy, szeroko dostępny model graficzny, połączony z wieloetapowym modelem myślącym, który przed generowaniem samego obrazku, przeprowadzał analizę. Umożliwiło to tworzenie infografik na użytecznym poziomie. Istotnym skokiem w jakości było lepsze generowanie tekstu, bo domyślnie modele graficzne miały z tym problem.
GPT obecnie przeskoczył Gemini w tej kwestii. Grafikę powyżej stworzył Chat GPT, po paru zapytaniach uzupełniających.
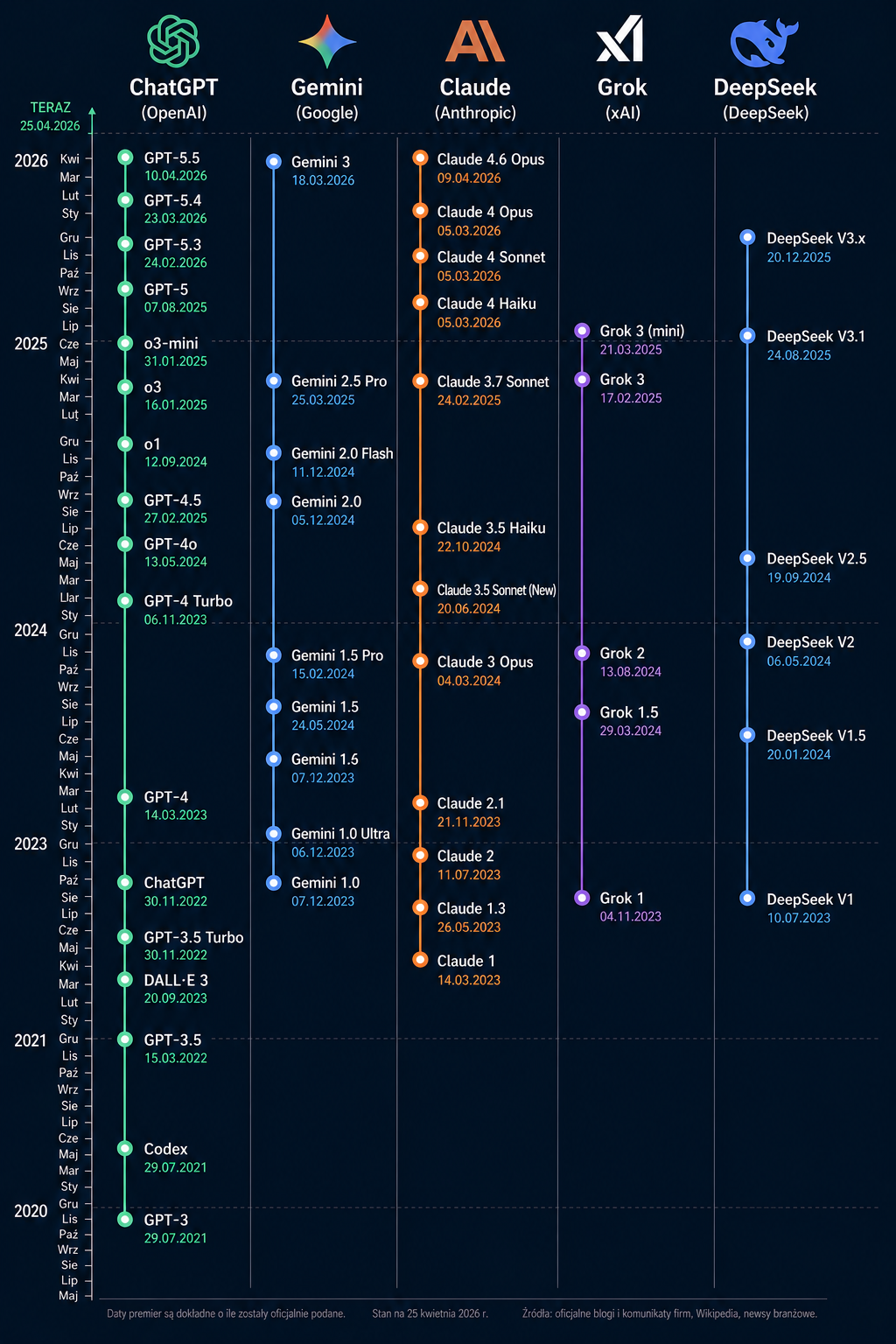
Dla lepszego porównania, pokazuje jaki efekt dostarczył Chat GPT i Gemini po tym samym zapytaniu: „Stwórz grafikę, osie czasu modeli jezykowych. Zrób tak, u góry nazwa firmy (rodziny modeli), Chat GPT, Gemini, Claude, Grok. DeepSeek, kazdy z 5 firm ma pionową linie, i daty premiery modeli. idź od dołu, tak ze teraźniejszość jest u góry ”
Poniżej Chat GPT:

A poniżej efekt działania Gemini.

Różnica jest kolosalna. Co prawda przy pierwszym zapytaniu, oba modele popełniły trochę błędów. Chat GPT nie podał nowszych modeli, natomiast sama grafika jest czystsza, a przede wszystkim, grafika nie wygląda jak typowa rzecz stworzona przez AI.
Natomiast grafika od Gemini jest pełna elementów charakterystycznych dla sztucznej inteligencji. Mamy więc dublujące się daty w głównej osi, dodatkowo każda oś ma dublującą się mini oś z innymi datami. Kolejnym problemem są ozdobniki, które na ogół nie sa potrzebne. W tym wypadku to tło nie wygląda źle, ale często takie rzeczy są problematyczne. Co prawda takie rzeczy da się łatwo naprawić, ale fajne jest to że GPT domyślnie robi to czego się oczekuje.
Przewaga GPT jest widoczna jeśli chodzi o ulepszanie grafiki. Za pomocą narzędzia od Open AI bez problemu udało mi się stworzyć w pełni użyteczną grafikę, (tę na początku artykułu). Co najważniejsze, ani razu nie zauważyłem żeby model „coś psuł”. W przypadku generowanie rzeczy za pomocą AI jest to istotne. Sytuacja gdy kolejna komenda psuje to co było wcześniej, wybija z rytmu, bo rodzi się wtedy wrażenie że Ai z daną rzeczą w ogóle nie jest w stanie z daną rzeczą poradzić.
Generowanie infografik to jedno z lepszych zastosowań modeli graficznych.
Co prawda za generowanie grafik nie odpowiada bezpośrednio model GPT 5.5. a GPT image 2.0, ale miał on premierę zaledwie dwa dni przed premierą głównego modelu, tak więc z punktu widzenia użytkownika jest to dość powiązany temat.
Co ważne, nowy model graficzny jest dostępny również w bezpłatnej wersji.
Chat GPT images 2.0.
Najnowszy model graficzny w ChatGPT to ChatGPT Images 2.0 (oparty na modelu gpt-image-2), który OpenAI ogłosiło zaledwie kilka dni temu, 21 kwietnia 2026 roku.
Images 2.0 to najnowocześniejszy model generowania obrazów OpenAI z ulepszonymi możliwościami renderowania tekstu, obsługą wielu języków i zaawansowanym rozumowaniem wizualnym.
Możliwości „myślenia”
Model ma zdolności rozumowania, które pozwalają mu przeszukiwać internet, tworzyć kilka obrazów z jednego promptu i weryfikować własne wyniki. Dzięki temu Images 2.0 potrafi tworzyć materiały marketingowe w różnych formatach oraz wielopanelowe komiksy.
Jakość i rozdzielczość
Obrazy mogą mieć rozdzielczość do 2K i być generowane w wielu proporcjach. OpenAI twierdzi, że przy użyciu Images 2.0 można tworzyć całe magazyny, a model obsługuje też języki niełacińskie.
Dostępne są dwa tryby pracy: Instant (szybki) oraz Thinking (z rozumowaniem).
Renderowanie tekstu
Model potrafi tworzyć materiały takie jak menu restauracyjne gotowe do natychmiastowego użycia, bez błędów ortograficznych, które przez lata były zmorą modeli graficznych. Wcześniejsze modele opierały się na architekturze dyfuzji, która rekonstruuje obraz z szumu i słabo radziła sobie z tekstem.
Tabele i dokumenty
Z perspektywy zwykłego użytkownika, możliwość wygenerowania użytecznej tabeli w AI często jest ważniejsza niż wyższe zdolności rozumowania i programowania danego modelu językowego. Funkcja ta istniała w starszych wersjach GPT, ale do tej pory dało się jedynie tworzyć proste tabelki.
Chat GPT 5 .5. potrafi od razu generować złożone skoroszyty, składające się z paru logicznie połączonych tabeli. I, co najważniejsze, model potrafi je modyfikować na podstawie kolejnych komend.

W tym wypadku, poprosiłem o stworzenie tabeli programów i aplikacji opierających się na sztucznej inteligencji. Poza główną tabelą, dostałem od razu arkusze z podsumowaniem tabeli, wykresem, listą tagów, słownikiem, opisem tabeli itd., mimo że o tym nie wspominałem (a te dodatkowe elementy są dość przydatne).

Od samego początku premiery Chat GPT 3.5, modele językowe były dużą pomocą przy tworzeniu tabel, bardzo użyteczna była pomoc przy pisaniu formuł. Natomiast wszystko trzeba było ręcznie kopiować. Funkcja generowania całej tabeli od razu, znacząco ułatwia zadanie. Tak stworzoną tabelę, można potem pobrać, i ręcznie modyfikować.
Na ten moment brakuje wygodnej, oficjalnej wtyczki od Open AI do modyfikowania arkuszy bezpośrednio w Excelu (taką funkcję posiada Claude), ale wydaje się że kwestią czasu jest jej wprowadzenie. Pewnym rozwiązaniem jest pobranie aplikacji Chat GPT czy codex, i praca na plikach z własnego dysku.
Generowanie ulotek i dokumentów

A poniżej efekt działania. Chat GPT stworzył dwustronną wersje broszury do druku. Na tym etapie, wymaga to wielu poprawek, a tak właściwie konieczne jest zrobienie wszystkiego ręcznie, ale mamy już solidną bazę do rozpoczęcia pracy. Należy zaznaczyć że jest to efekt jednej komendy, tak więc jest potencjał na osiąganie lepszych efektów gdy się więcej popracuje.

A poniżej wersja zrobiona jako grafika,a nie jako dokument.

Tworzenie programów
Przystępując do pisania tego tekstu, testowałem zdolności generowania kodu uruchamianego bezpośrednio w aplikacji. I niestety się zawiodłem. Możliwości były minimalnie większe niż w starszych wersjach, natomiast często program w ogóle nie chciał się uruchomić. Takie problemy w Gemini czy Claude pojawiają się dopiero przy 6-10 poprawce, w Chat GPT błędy wyskakiwały przy pierwszej lub drugiej komendzie, mniej więcej w 40% przypadków. Oczywiście, dla programistów nie jest to problemem, stosując lepsze prompty można błędów unikać, natomiast funkcja uruchamiania kodu bezpośrednio w aplikacji jest przeznaczona głównie dla osób które nie umieją programować.
Ta funkcja służy np. do tego żeby stworzyć szybko prototyp strony, przygotować interaktywny dashboard pokazujący dane i informacje w ładnej formie, czy żeby się bawić tworzyć proste gierki, co daje motywacje do pobrania bardziej złożonych narzędzi.
GPT-5.5 i Codex. Widać wzrost jakości, gdy model operuje w środowisku programistycznym.
Jednym z największych beneficjentów nowego modelu jest Codex, czyli narzędzie OpenAI do agentycznego programowania. W Codexie GPT-5.5 może teraz wchodzić w interakcje z aplikacjami webowymi, testować przepływy, klikać strony, wykonywać zrzuty ekranu i na podstawie tego tworzyć lepsze wersje, co widzi, aż do ukończenia zadania.
Jedna z testowanych funkcji wyróżnia się szczególnie. Po tym, jak GPT-5.5 zbudował aplikację z błędem, Codex otworzył sesję przeglądarki, wizualnie nawigował po aplikacji, zidentyfikował problem i autonomicznie go naprawił. Model używał własnego kursora, klikał przez funkcje, weryfikował poprawki wizualnie i raportował, gdy wszystkie testy przeszły pomyślnie.
Ponad 85% pracowników OpenAI korzysta z Codexa co tydzień w różnych działach, w tym inżynierii, finansach, komunikacji, marketingu, nauce o danych i zarządzaniu produktem. Liczba ta obrazuje, że GPT-5.5 w Codexie przestał być narzędziem wyłącznie dla programistów.
Jak Chat GPT 5.5. radzi sobie z programowaniem?
Możliwości nowego modelu od Open AI dobrze ukazuje poniższy film.
Najlepszym przykładem z filmu jest digital twin ziemi (cyfrowy bliźniak), czyli program pokazujący mapę całego świata. Chat GPT korzystał tu z gotowych bibliotek, ale nadal jest to imponujące.

Drugim ciekawym przykładem jest trójwymiarowa gra, stworzona na podstawie dwóch promptów.

Skąd pochodzi GPT 5.5 i czym różni się od poprzedników?
Żeby zrozumieć, dlaczego GPT-5.5 jest czymś więcej niż zwykłą aktualizacją, warto spojrzeć wstecz. Modele z rodziny GPT-5.x wypuszczane od końca 2025 roku, czyli 5.1, 5.2, 5.3 i 5.4, były ulepszonymi wersjami budowanymi na tym samym bazowym modelu. GPT-5.5 jest pierwszym gruntownie przetrenowanym modelem bazowym od czasów GPT-4.5. Architektura, korpus danych treningowych i cele zorientowane na działanie agentów zostały przeprojektowane od podstaw.
Model jest natywnie omnimodalny, co oznacza, że przetwarza tekst, obrazy, dźwięk i wideo w ramach jednej, zunifikowanej architektury. Nie jest to już model tekstowy z doklejonymi możliwościami rozumienia innych mediów. Wszystkie modalia są traktowane od samego początku jako pełnoprawne wejście.
Wewnętrznie w OpenAI model nosił kryptonim „Spud”. Publicznie zaprezentowany został jako odpowiedź na Claude Opus 4.7 od Anthropic, który pojawił się dokładnie tydzień wcześniej i przejął koronę w dziedzinie programowania. Czas premiery GPT-5.5 nie był przypadkowy.
Co potrafi GPT-5.5? Ogólne zdolności i zastosowania
Kluczowym słowem opisującym GPT-5.5 jest agentyczność. Model nie czeka, aż użytkownik poprowadzi go krok po kroku przez zadanie. Zamiast dokładnego zarządzania każdym etapem pracy, można przekazać GPT-5.5 nieuporządkowane, wieloczęściowe zadanie i zaufać, że sam zaplanuje działanie, skorzysta z narzędzi, sprawdzi własną pracę, poradzi sobie z niejasności ami i będzie kontynuował aż do ukończenia.
Oznacza to, że zamiast pisać: „Przeanalizuj ten plik, a potem zrób zestawienie, a potem stwórz wykres”, można po prostu powiedzieć: „Oto sześć miesięcy danych sprzedażowych. Znajdź anomalie i zaproponuj działania korygujące”. Model samodzielnie ustali plan, wybierze narzędzia i dostarczy gotowy wynik.
Szczególnie silne postępy widać w agentycznym programowaniu, korzystaniu z komputera, pracy biurowej i wstępnych badaniach naukowych, czyli obszarach, w których postęp zależy od wnioskowania w szerokim kontekście i podejmowania działań przez dłuższy czas.
OpenAI podaje konkretne przykłady wewnętrznego wdrożenia. Zespół finansowy firmy użył Codexa z GPT-5.5 do przejrzenia 24 771 formularzy podatkowych K-1, liczących łącznie 71 637 stron, przyspieszając to zadanie o dwa tygodnie w porównaniu z poprzednim rokiem. Pracownik z działu sprzedaży zautomatyzował generowanie tygodniowych raportów biznesowych, oszczędzając od pięciu do dziesięciu godzin pracy tygodniowo.
Wcześniejsze zespoły testujące model mogły weryfikować kod tworzony metodą „vibe coding”, przeglądać tysiące dodatkowych dokumentów i oszczędzać do dziesięciu godzin pracy tygodniowo.
Benchmarki GPT 5.5.
Liczby robią wrażenie, ale wymagają kontekstu. GPT-5.5 nie wygrywa wszędzie i uczciwa ocena wymaga spojrzenia na całościowy obraz.
Mocne strony modelu:
Na Terminal-Bench 2.0, który testuje złożone przepływy pracy w wierszu poleceń wymagające planowania, iteracji i koordynacji narzędzi, GPT-5.5 osiąga wynik 82,7%, ustanawiając nowy rekord wśród publicznie dostępnych modeli.
Szczególnie imponujący jest skok w rozumieniu długich kontekstów. Na teście MRCR v2 przy kontekście jednego miliona tokenów wynik poprawił się z 36,6% w GPT-5.4 do 74,0%, co oznacza więcej niż podwojenie skuteczności. To przełomowa zmiana dla zastosowań wymagających analizy całych baz kodu lub obszernych zbiorów dokumentów.
Na GDPval, który testuje agentów w 44 prawdziwych zawodach, od finansów po badania prawne i zarządzanie produktem, GPT-5.5 osiąga 84,9%. Na Tau2-bench Telecom, testującym złożone przepływy obsługi klienta, wynik wynosi 98,0% bez żadnego dostosowywania promptów.
W bioinformatyce i genetyce model również wyznacza nowe standardy. Na BixBench osiąga 80,5% wobec 74,0% poprzednika, a na GeneBench poprawia wynik z 19,0% do 25,0%.
Gdzie GPT 5.5 przegrywa z konkurencją.
Nie wszystkie benchmarki są po stronie GPT-5.5. Claude Opus 4.7 osiąga 64,3% na SWE-Bench Pro wobec 58,6% GPT-5.5, co oznacza, że model Anthropic lepiej radzi sobie z rozwiązywaniem prawdziwych problemów z repozytoriów GitHub. Claude prowadzi też na MCP Atlas, który testuje orkiestrację wielu narzędzi, uzyskując 79,1% wobec 75,3%, a na wielojęzycznym rozumieniu języka naturalnym Claude i Gemini wyraźnie wyprzedzają nowy model OpenAI.
Wśród deweloperów reakcja jest wyważona, a nie entuzjastyczna. Pojawiają się głosy, że model jest skłonny do bardziej pewnych siebie błędów, czyli tak zwanej konfabulacji, co w agentycznych przepływach pracy może być groźniejsze niż zatrzymanie i zadanie pytania.
Dostępność i cennik
GPT-5.5 jest dostępny dla płacących subskrybentów OpenAI, w tym użytkowników planów Plus, Pro, Business i Enterprise w ChatGPT oraz Codex. Wersja GPT-5.5 Pro jest ograniczona do planów Pro, Business i Enterprise.
Kwestia cennika jest jednym z bardziej kontrowersyjnych elementów premiery. Cena API wzrosła z 2,50 i 15 dolarów do 5 i 30 dolarów za milion tokenów odpowiednio wejściowych i wyjściowych, co stanowi największy jednorazowy wzrost ceny w całej serii GPT-5.x.
OpenAI argumentuje, że ten wzrost jest łagodzony przez wyższą efektywność tokenową. GPT-5.5 używa znacznie mniej tokenów do osiągnięcia wyników porównywalnych z GPT-5.4. Firma aktywnie absorbuje część zysku z efektywności tokenów, żeby utrzymać wartość dla subskrybentów, co oznacza, że użytkownicy planu Plus mogą w danym miesiącu wykonać więcej pracy, nawet jeśli model jest droższy po stronie API.
Realne koszty dla zespołów pozostają tematem dyskusji. Przy 10 milionach tokenów wyjściowych miesięcznie GPT-5.5 kosztuje 300 dolarów, a Claude Opus 4.7 kosztuje 250 dolarów. Jeśli jednak lepsza agentyczna wydajność GPT-5.5 oznacza 25% mniej potrzebnych iteracji, różnica kosztów się zaciera.
Bezpieczeństwo
GPT-5.5 jest pierwszym modelem OpenAI, który przeszedł przez pełny nowy zestaw zabezpieczeń przygotowany przez firmę na erę modeli agentycznych. Model oceniano w oparciu o pełny zestaw ram bezpieczeństwa i gotowości, przeprowadzono testy z udziałem wewnętrznych i zewnętrznych specjalistów od „red teamingu”, dodano ukierunkowane testy zaawansowanych możliwości w dziedzinie cyberbezpieczeństwa i biologii, a przed premierą zebrano opinie od prawie 200 zaufanych partnerów z wczesnym dostępem.
OpenAI zakwalifikowało zdolności modelu w zakresie biologii, chemii i cyberbezpieczeństwa jako „wysokie” według własnych ram oceny ryzyka. Jednocześnie udostępniło specjalną ścieżkę dla profesjonalistów zajmujących się bezpieczeństwem cyfrowym, którzy chcą korzystać z możliwości modelu do pracy obronnej.
Sytuacja Open AI po premierze GPT.5.5.
Trudno oceniać GPT-5.5 w izolacji od otoczenia rynkowego. Premiera, która nastąpiła zaledwie sześć tygodni po debiucie GPT-5.4, podkreśla, jak mocno czołowe firmy rywalizują o klientów korporacyjnych i jak ich modele coraz bardziej ewoluują przez ciągłe aktualizacje.
Firma podała również, że ma 4 miliony aktywnych użytkowników Codexa i 9 milionów płacących klientów biznesowych w ChatGPT. ChatGPT ma ponad 900 milionów tygodniowo aktywnych użytkowników i ponad 50 milionów subskrybentów.
Analitycy branżowi zwracają uwagę, że tempo wydań nie jest przypadkowe. Sześciotygodniowy rytm wypuszczania nowych modeli sprawia, że przedsiębiorstwa nie zdążają skonfigurować jednego rozwiązania, zanim pojawia się następne. To strategia, która wymusza ciągłą zależność od platformy i utrudnia migrację do konkurencji.
Greg Brockman otwarcie mówił o projekcie „super aplikacji”, która ma połączyć ChatGPT, Codex i przeglądarkę AI w jedno zintegrowane środowisko pracy.
Chat GPT 5.5. opinie
W mojej ocenie, ogromną zaletą nowego modelu jest lepsza obsługa tabel, oraz dokumentów. W połączeniu z najlepszym na rynku generowaniem infografik oraz obrazów (pomijając aplikacje dedykowane do tego), Chat GPT 5.5. ma solidne podstawy żeby wrócić na pozycje lidera.
Możliwości programowania również się zwiększyły, ale żeby je zauważyć, trzeba mieć minimalną wiedzę o ty jak działają programy.
Wśród recenzentów i użytkowników pojawiają się powtarzające się wątki, które warto podsumować.
Na plus zdecydowanie idzie skok agentyczności. Model naprawdę lepiej radzi sobie z wieloetapowymi zadaniami bez ciągłego naprowadzania. Poprawa rozumienia długich kontekstów jest też skokowa, a nie ewolucyjna. Efektywność tokenowa jest realna i doceniana przez programistów płacących za API.
Na minus wskazuje się podwójną cenę API, która boli szczególnie mniejsze zespoły. Konfabulacja przy pewnych sobie odpowiedziach jest ryzykiem, na które zwracają uwagę doświadczeni deweloperzy. W prawdziwych zadaniach programistycznych opartych na repozytoriach GitHub Claude Opus 4.7 wciąż jest lepszy. Recenzenci zauważają też, że model radził sobie gorzej przy pełnostackowych aplikacjach w testach praktycznych.
Reakcja deweloperów jest wyważona, a nie euforyczna. Pojawiają się głosy, że skok jest większy, niż sugeruje sam numer wersji, bo jest to pełne przetrenowanie bazy, a nie kolejna warstwa post-trainingu. Ale doświadczeni praktycy studzą entuzjazm: Terminal-Bench to nie to samo co SWE-Bench.
Uczciwa ocena GPT-5.5 brzmi: to model, który robi dokładnie to, do czego jest zaprojektowany, czyli agentyczną pracę z narzędziami w środowiskach terminalowych i biurowych. Jeśli Twój workflow polega na długich, wieloetapowych zadaniach wymagających autonomicznego działania, GPT-5.5 jest prawdopodobnie najlepszą dostępną opcją. Jeśli pracujesz na złożonych repozytoriach kodu, rozwiązujesz wieloplikowe bugi lub potrzebujesz głębokiego rozumowania bez scaffoldingu, Claude Opus 4.7 nadal oferuje silniejsze możliwości.
Oba modele definiują aktualny stan możliwości AI. Wybór między nimi to nie pytanie o to, który jest lepszy absolutnie, ale o to, który lepiej pasuje do konkretnego zastosowania.


